0. 개요
프로젝트를 진행하면서 소수의 test user 는 크게 문제 없었지만
이벤트 프로모션 알람을 신청한 사람이 100000명까지 늘어나면 이벤트 오픈 시간과 최대한 가깝게 모든 알람을 사용자들이 받아볼 수 있을지 의문이였다.
참고로 나는 알림을 받을 target token 생성을 위해 FCM 프론트 서버를 간단히 구현해두었다.
로그로 target token 을 확인해볼 수 있다.
https://github.com/lielocks/FCM-react
1. 모니터링 도구로 cloud watch 도입
memory 사용량 + cpu 사용량 실시간으로 분석하려고 했기 때문이다.

혹시 cloud watch config script 를 잘 짰는데 위 사진처럼 404 error 가 난다면
https://github.com/aws/amazon-cloudwatch-agent/issues/1435
Metadata error logs in Cloudwatch agent - 404 EC2MetadataError: failed to make EC2Metadata request · Issue #1435 · aws/amazon-
Describe the bug cloudwatch agent logs throw repeated errors. status code: 404, request id: D! should retry true for imds error : EC2MetadataError: failed to make EC2Metadata request This only happ...
github.com
해당 글을 참고해주면 된다. (특정 agent 버전에서 발생하는 버그 문제인 것 같다.)
2. 문제 상황 및 Async + Custom Thread Pool 도입

처리시간은 186분으로 3시간이 넘게 걸렸고 CPU 평균은 96.3%, 최대는 100% 그리고 Memory 사용량도 어마어마하다!
@Async
public void sendMessageTo(String targetToken, String title, String body) throws IOException {
String message = makeMessage(targetToken, title, body);
OkHttpClient client = new OkHttpClient();
RequestBody requestBody = RequestBody.create(message, MediaType.get("application/json; charset=utf-8"));
Request request = new Request.Builder()
.url(API_URL)
.post(requestBody)
.addHeader(HttpHeaders.AUTHORIZATION, "Bearer " + getAccessToken())
.addHeader(HttpHeaders.CONTENT_TYPE, "application/json; UTF-8")
.build();
Response response = client.newCall(request).execute();
log.info("response {}", response.body().string());
}
첫번째로 Async 를 도입했다.
그러다 OkHttpClient 로 call 을 날리는 execute() 부분을 유심히 들여다봤다.
execute() 동기 작업
- execute() 메서드는 blocking 호출로, 메시지가 전송될 때까지 현재 thread가 멈추게 된다.
firebase 도 비동기로 실행되는 메서드가 있지 않을까 찾아보다

FirebaseMessaging class 에 sendAsync 라는 비동기 전송 로직을 발견하였다.
따라서 Firebase Admin SDK 의 FirebaseMessaging 클래스를 사용해서 수정해줬다.
이때 gradle 버전을 꼭 유의해야 한다 !
현재 프로젝트 : Spring Boot 3.0.4, spring-core:6.0.6
implementation 'com.google.firebase:firebase-admin:9.2.0'
implementation 'org.apache.httpcomponents.client5:httpclient5:5.2'
implementation 'org.apache.httpcomponents.core5:httpcore5:5.3'
httpclient 와 httpcore 를 이 버전으로 맞춰주지 않으면
Caused by: java.lang.ClassNotFoundException: org.apache.hc.client5.http.classic.HttpClient
해당 에러가 지속적으로 발생한다.
@Async
public void sendMessageTo(String targetToken, String title, String body) {
try {
Message message = Message.builder()
.setToken(targetToken)
.setNotification(Notification.builder()
.setTitle(title)
.setBody(body)
.build())
.build();
// sendAsync를 통해 비동기로 전송
FirebaseMessaging.getInstance().sendAsync(message)
.addListener(() -> log.info("Successfully sent message to {}", targetToken), Runnable::run);
} catch (Exception e) {
log.error("Error sending message to {}: {}", targetToken, e.getMessage());
}
}
sendAsync() 비동기 작업
- 메시지를 전송하는 동안 호출 스레드를 차단하지 않고, 별도의 비동기 작업으로 처리된다.
- sendAsync()는 Java의 CompletableFuture를 반환하여 비동기적으로 처리해준다.
여기까지 적용 후 다시 테스트를 진행해봤을때
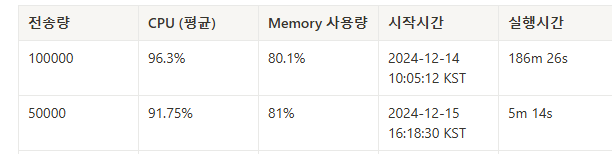
5만건의 호출은 5m 14s 까지 단축되었고
10만건의 호출부터 heap out of memory 에러가 나며 몇초후의 호출들 모두 실패하였다.
Async 를 도입하면서 Thread Pool이 과부하 상태에 빠져서 OOM 에러가 발생한 것 같았다.
지금처럼 @Async 어노테이션을 사용할 때 별도의 Executor 를 선언하지 않으면,
Spring Boot 에서 자동으로 생성해주는 ThreadPoolTaskExectuor 를 사용하게 된다.
아래는 ThreadPoolTaskExectuor 기본 property 설정이다.
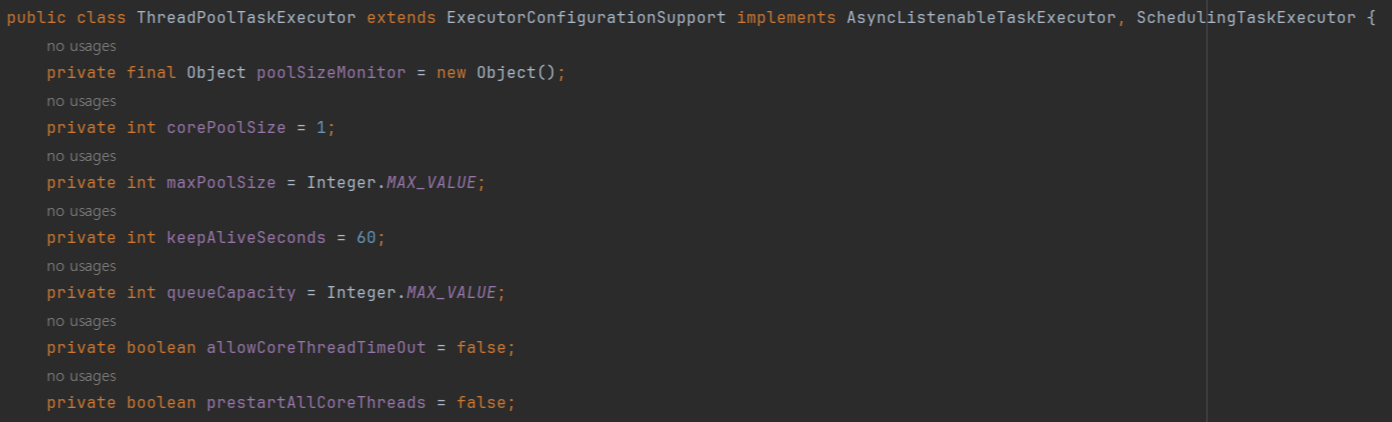
이에 corePoolSize 와 maxPoolSize, queueCapacity 를 어떻게 커스텀할지 고민이 들었다.
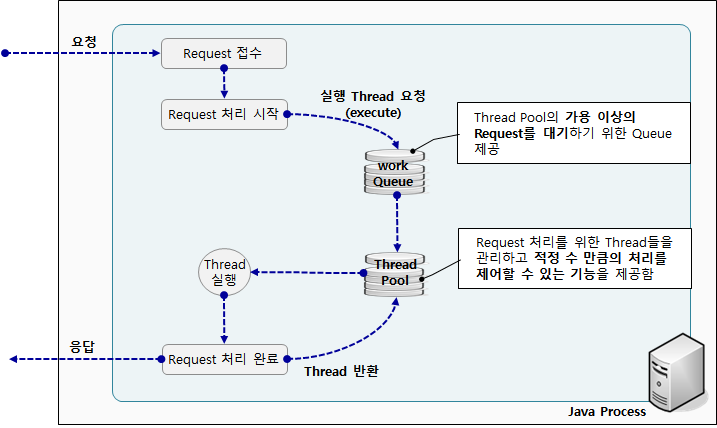
[ ThreadPoolTaskExecutor의 기본적인 동작원리 ]
1.ThreadPool에 작업(task)을 등록하면 설정한 corePoolSize 만큼 ThreadPool에 Thread가 있는지 확인한다. (corePoolSize를 설정하지 않으면 기본값은 1이다.)
2. corePoolSize 보다 작은 수 만큼의 Thread가 ThreadPool에 존재한다면 새로운 Thread를 ThreadPool에 생성하고 작업을 할당한다.
- 설령 ThreadPool 안에 Thread가 대기(idle)상태로 존재해도 Thread 숫자가 적으면 새로운 Thread를 생성하고 작업을 할당한다.
- 만약 corePoolSize 이상의 Thread가 존재하면 ThreadPool안에 대기 상태인 Thread에게 작업을 할당한다.
3. ThreadPool에 존재하는 모든 Thread가 작업 중(=대기 상태의 Thread가 하나도 없는 상태)이라면 BlockingQueue에 작업(task)을 넣어 작업을 대기시킨다.
4. 작업 중인 Thread가 작업을 마치면 BlockingQueue에 처리해야할 작업(task)가 있는지 확인한다.
큐가 비어있지 않으면(=처리해야할 작업이 있으면) 큐로 부터 작업을 가져와서 다시 작업을 수행하는 것을 반복한다.
5. 작업이 급격하게 많이 발생해서 설정한 큐의 크기 만큼 큐에 작업이 가득 차게되었고 가득 차있음에도 불구하고 더 작업이 요청되면 ThreadPool에 Thread가 1개 더 생성된다.
- 현재 ThreadPool의 Thread 수가 maxPoolSize보다 작은 경우에는 Thread를 추가하지만, 현재 ThreadPool의 Thread 수가 maxPoolSize에 도달한 경우에는 더 이상 Thread를 생성할 수 없고 큐에 대기시킬 수도 없기 때문에 TaskRejectedException(RejectedExecutionException을 상속한 예외)이 발생한다.
- 예외가 발생하는것이 기본 설정이고 다른 정책을 지정해줄 수 있다.
ex) CallerRunsPolicy : ThreadPool에 작업을 넣으려고 한 Thread에서 직접 실행하는 전략
6. 예외까지 발생할 정도는 아니고 Thread가 corePoolSize 보다 큰 개수 만큼 Thread가 생성된 상태에서 큐에 쌓인 작업을 잘 소화하여 큐를 비울 수 있게 되었다고 하면, keepAliveTime(기본 값 60초)동안 corePoolSize 수보다 초과하여 생긴 Thread들은 대기 상태로 대기하다가 ThreadPool에서 제거된다.
- 전체 요청 수: 10만 건의 알림 호출
- 목표 시간: 10~15분 (600초에서 900초 사이)
- 처리 속도 요구:
- 10만 건을 10분(600초) 동안 처리하려면, 초당 처리해야 하는 요청 수:
- 100,000 알림 / 600 초=166.67 요청/초
- 10만 건을 15분(900초) 동안 처리하려면, 초당 처리해야 하는 요청 수:
- 100,000 알림 / 900 초 ≈ 111.11 요청/초
- 10만 건을 10분(600초) 동안 처리하려면, 초당 처리해야 하는 요청 수:
할인 이벤트에 대한 사용자의 신청을 미리 받아두고 알림 이벤트를 발생시키기 때문에 알림 갯수는 예측 가능하다.
10만개의 알림을 한꺼번에 동시에 발생하고 이벤트 시간 10분 ~ 15분 의 정도로 가깝게 발생시키는 것을 목표로 잡았다.
현재 10만개의 알림이 동시에 발생한다고 가정하기에, queueCapacity와 maxPoolSize 를 사용해 스레드 갯수를 유동적으로 조정하는 방법이 맞을까 그냥 default 로 두는것이 맞을지 고민이 되었다.
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
@Bean(name = "alarmExecutor")
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(40);
executor.setThreadNamePrefix(CommonConstants.ALARM_TASK_EXECUTOR_NAME);
executor.initialize();
return executor;
}
}
n개의 스레드 갯수를 고정하여 항시 가용 가능한 최대 스레드를 풀로 사용, 최대한 빠르게 처리하도록 하는 방법이 더 나은 방향이라고 판단했다.
따라서 큐 사이즈를 기본 설정인 Integer.MAX_VALUE 로 유지하고, corePoolSize 만을 조절하여 최적의 스레드 갯수를 지정하고자 했다.
하지만 장단점이 있다.
- 유동적 조정: 메모리 사용량 절약 vs 처리 속도 저하 (큐에 의존)
- 고정된 스레드 풀: 처리 속도 빠름 vs 급격한 부하 시 Out of Memory 위험
고민하다가 여러 케이스들을 테스트해본 결과이다.

memory 는 원래도 61% 정도의 사용률을 평균으로 가지고 있어서 70% 초중반의 사용률을 임계점으로 잡았다.
< Test 지표 - jvm Thread, maxPoolSize, QueueCapacity 기준 >
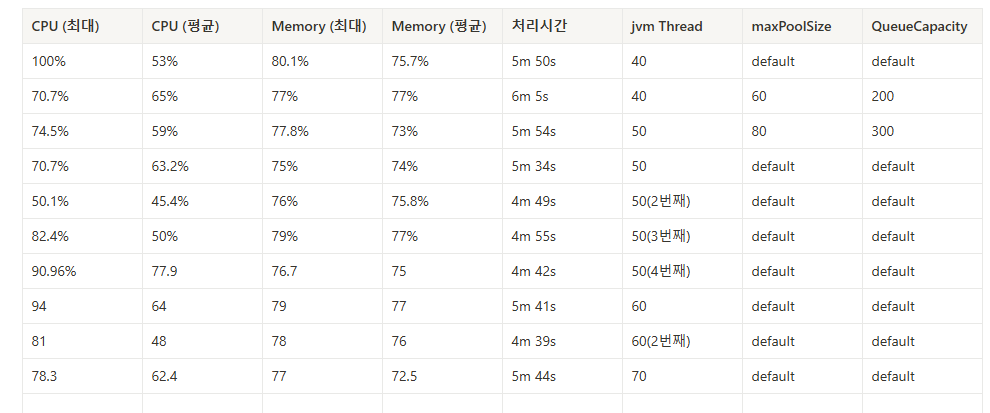
최적의 corePoolSize 는 50개로 2번째 시도에서 cpu 사용량이 확연히 줄었다.
2번째 실행에서는 C1 Compiler 덕분에 CPU 사용량이 낮아진듯하다.
그럼 그 이후의 시도에서는 더 cpu 를 효율적으로 사용하겠구나 생각하고 3번째, 4번째까지 시도를 했으나 ,
하지만 오히려 첫번째 시도때보다 cpu 사용량이 치솟았다 !
왜 그럴까.. 고민을 해보다 GC를 살펴봤다.

- Survivor 영역 (S0C, S1C):
- S0C = 8192.0 KB, S1C = 8192.0 KB (각 Survivor 영역의 크기)
- S0U = 4942.0 KB, S1U = 0.0 KB
- 현재 Survivor 0에 약 4.9 MB 데이터가 남아 있고 Survivor 1은 비어있다.
- Eden 영역 (EC, EU):
- EC = 65536.0 KB, EU = 29876.2 KB
- Eden 영역의 총 크기는 64 MB, 사용량은 약 29 MB이다.
- Eden 영역이 약 45% 정도 사용 중이다.
- EC = 65536.0 KB, EU = 29876.2 KB
- Old Generation (OC, OU):
- OC = 163840.0 KB, OU = 149583.8 KB
- Old 영역의 총 크기는 160 MB, 사용량은 약 149 MB입니다.
- Old Generation이 91% 이상 차있는 상태이다.
- 이는 Full GC가 빈번히 발생할 수 있는 조건이다.
- OC = 163840.0 KB, OU = 149583.8 KB
Metaspace 영역
- Metaspace (MC, MU):
- MC = 101952.0 KB, MU = 101324.5 KB
- Metaspace 총 용량이 약 101 MB, 사용량은 101 MB에 근접하다.
- Metaspace에 거의 여유 공간이 없다.
- MC = 101952.0 KB, MU = 101324.5 KB
- Compressed Class Space (CCSC, CCSU):
- CCSC = 13824.0 KB, CCSU = 13449.8 KB
- Compressed Class Space의 사용량이 약 97% 이다.
- CCSC = 13824.0 KB, CCSU = 13449.8 KB
GC 상태
- Young GC (YGC, YGCT):
- YGC = 3191, YGCT = 37.900 초
- Young GC는 3191회 발생했고, 총 소요 시간은 약 37.9초 이다.
- Young GC가 비교적 빈번하게 발생하고 있으며, Eden 영역의 빠른 소진으로 인해 Young GC가 트리거되고 있다.
- YGC = 3191, YGCT = 37.900 초
- Full GC (FGC, FGCT):
- FGC = 257, FGCT = 70.068 초
- Full GC가 257회 발생했으며, 총 소요 시간은 약 70.1초 이다.
- Old Generation의 높은 사용률로 인해 Full GC가 빈번히 발생하고 있다.
- FGC = 257, FGCT = 70.068 초
- 전체 GC 시간 (GCT):
- GCT = 107.967 초
- 전체 GC 시간은 약 108초 이다.
- GCT = 107.967 초
결국 Old Generation 이 91% 이상 차 있어 Full GC가 자주 발생하고 있어서 나타나는 문제점 인 것 같다.
Young GC도 빈번하게 발생하고 있고 Full GC 발생 횟수가 많고 총 시간이 길어지고 있었다.
알림 이벤트를 지속적으로 발생시키면서 Old Generation이 빠르게 채워지고 Full GC가 자주 발생하는 상황인 것이었다.
3. C1 Compiler 최적화
2번째 시도에서 처럼 C1 Compiler 를 가장 최적화해서 사용하는 방법으로 10만건을 지속적으로 보내지 말고
5000건 정도를 3~5번 정도를 보내서 C1 Compiler가 충분히 최적화된 바이트코드를 생성해 놓도록 하고 이후 들어오는 100,000건의 알림 처리 속도를 향상시켜 보자.
아래는 테스트 결과이다.
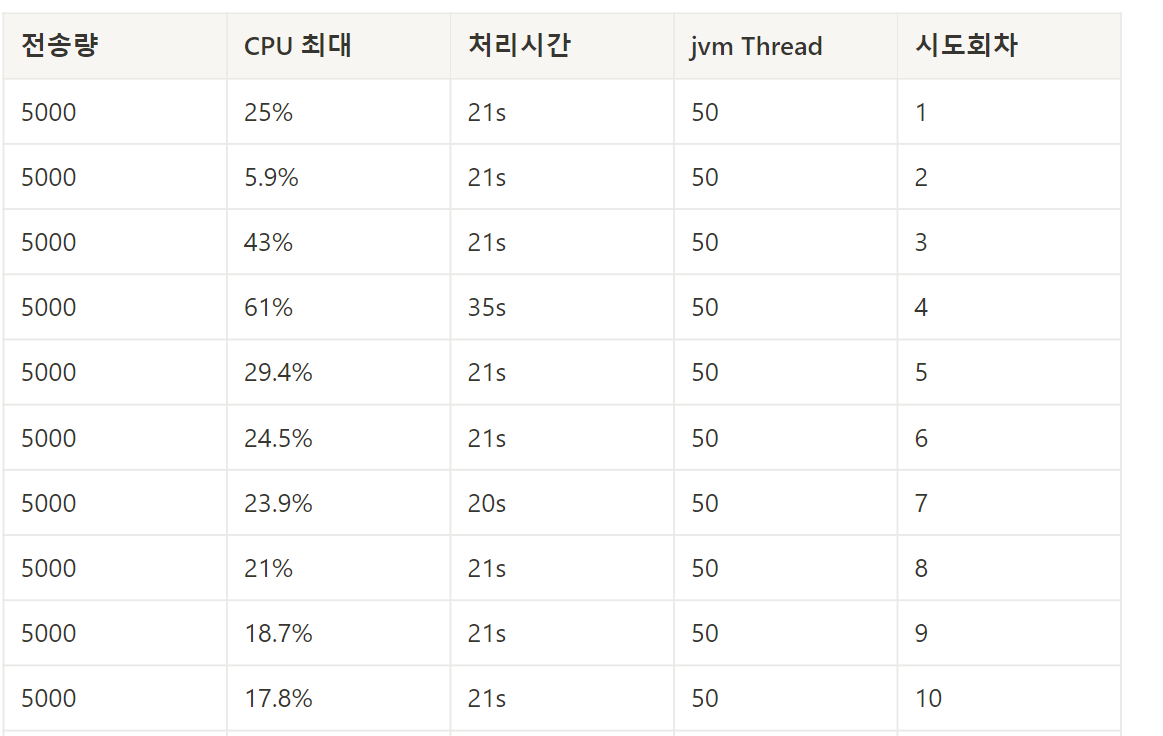
이번에도 2번째 시도에서 CPU 사용량이 극적으로 감소(25 → 5.9%) 하고 있음을 관찰할 수 있다.
C1 Compiler가 초기에는 컴파일 과정을 거치면서 CPU 사용량이 급격히 감소하는 효과를 볼 수 있지만,
3번째 이후 시도에서는 CPU 사용량이 다시 증가(43, 61%) 하다가
후반부(7~10 시도)로 갈수록 CPU 사용량이 21 → 17.8% 로 점점 감소하고 있다.
✔ 7번째에서 10번째의 시도로 warm up 했을때 C1 Compiler가 Hotspot 메서드를 점진적으로 최적화하고 있는 듯 하였다.
4. 결론
따라서 180분이 넘게 걸리던 10만건의 알림 발생건수를 5m 34s 까지 줄여봤지만
GC 알고리즘 튜닝이나 ,
현재 알림 이벤트로 사용하는 비동기 스레드와 Firebase Message Server의 firebase-default 스레드가 어떤식으로 매핑되는지도 꼼꼼하게 살펴서 CPU 사용량을 최대한 안정시키는 것이 남은 숙제이다 !
< 대용량 알림 개선기 (2) > 에서 이어집니다
reference : https://blog.naver.com/bumsukoh/222175557879 https://jeongpro.tistory.com/253 https://brunch.co.kr/@springboot/401#comments