0. 개요
현재 프로젝트는 쇼핑몰과 비슷한 도메인 특성상 가장 인기 있는 상품들이 홈화면 첫 번째 페이지에 계속 로드되며 이 데이터의 인기 순위 변동이 크지 않고,
가장 많은 JOIN 문으로 엮여있는 복잡한 쿼리이자 자주 호출되는 API 였기 때문에 매번 사용자가 조회할 때마다 데이터를 전달하는 것보다 고정된 데이터를 주기적으로 업데이트하고 이를 캐시로 제공하면 좋겠다고 생각했다.
- Local Cache
- 서버마다 캐시를 따로 저장
- 다른 서버의 캐시를 참조하기 어려움
- 속도 빠름
- 로컬 서버 장비의 Resource를 이용한다. (Memory, Disk) - Global Cache
- 여러 서버에서 캐시 서버 접근 및 참조 가능
- 별도의 캐시 서버 이용 → 서버 간 데이터 공유가 쉬움
- 네트워크 트래픽을 사용해야 해서 로컬 캐시보다는 느리다.
- 데이터를 분산하여 저장 가능
캐시는 크게 로컬 캐시와 글로벌 캐시로 나뉘는데, 현재는 서버가 모놀리식으로 다른 서버의 캐시를 참조할 일이 없어서
Redis 도입은 오버스펙 같았다.
더 빠른 성능을 가져올 수 있는 로컬 캐시 Spring Cache 그리고 로컬 캐싱에 특화된 캐싱 라이브러리인 Caffeine을 이용하고자 한다.
@Getter
@AllArgsConstructor
public enum CacheType {
SORT_PAGE_CACHE("sortPageCache", 30, 500); // 만료 시간(30분)
private final String cacheName;
private final int expireAfterWrite;
private final int maximumSize;
}
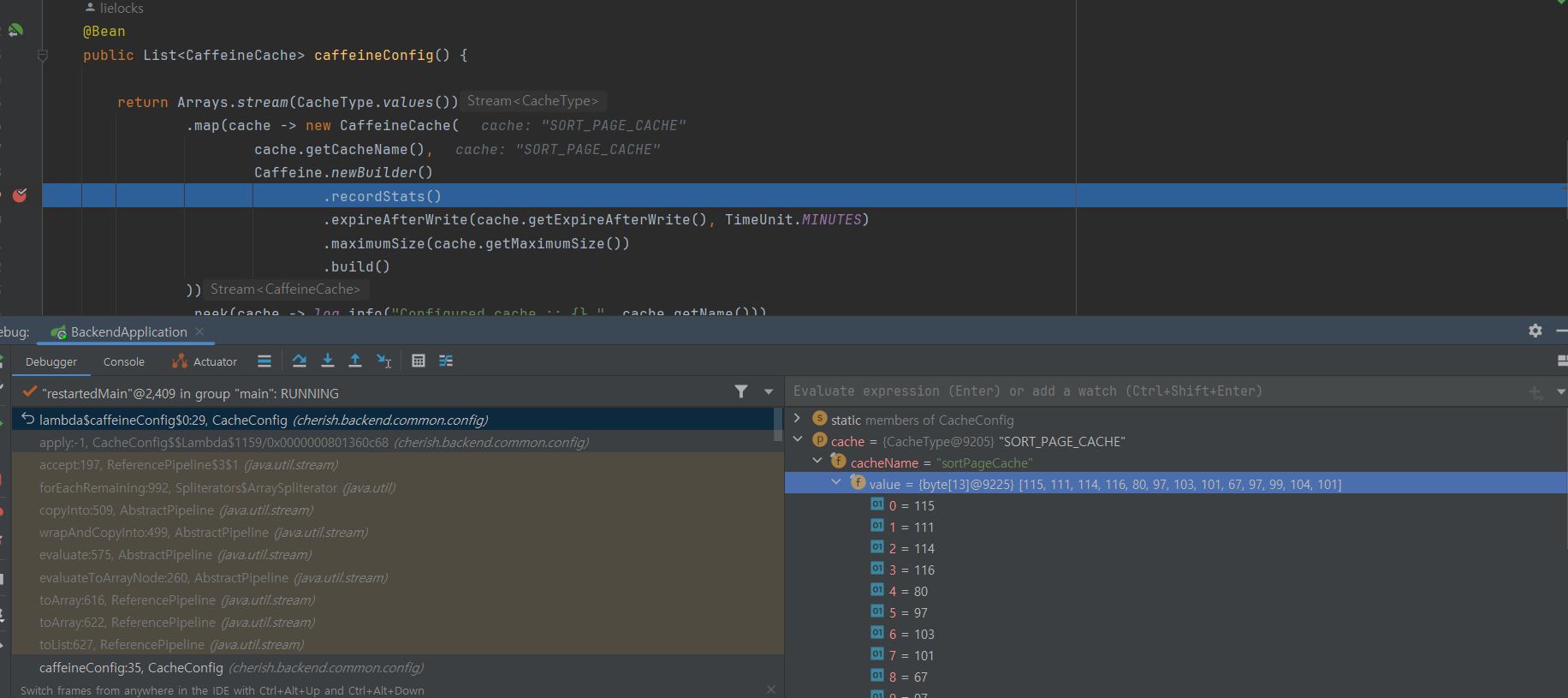
CachType 으로 지정한 cache key 와 value가 잘 적용이 되는지는
spring actuator 를 도입하거나 CacheConfig 디버깅을 통해 간단하게 확인할 수 있다.
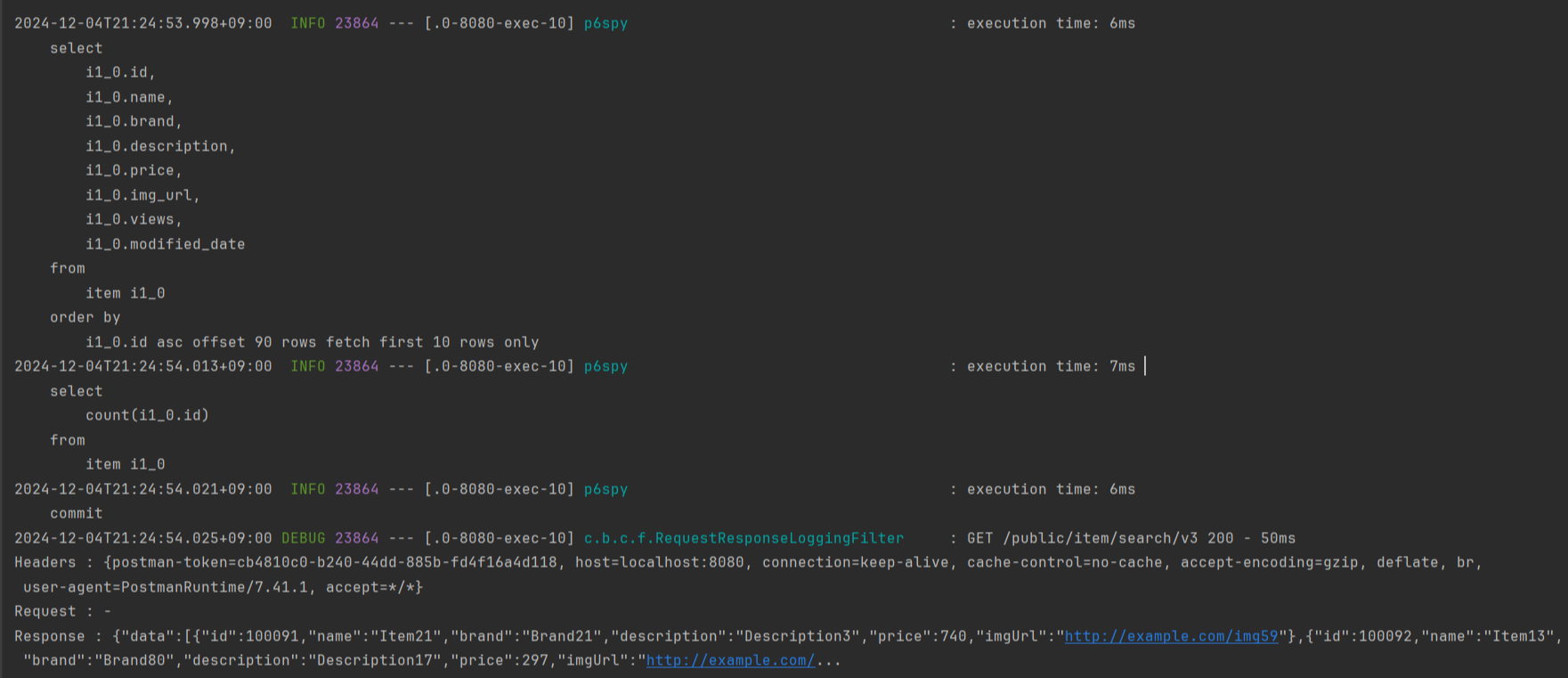
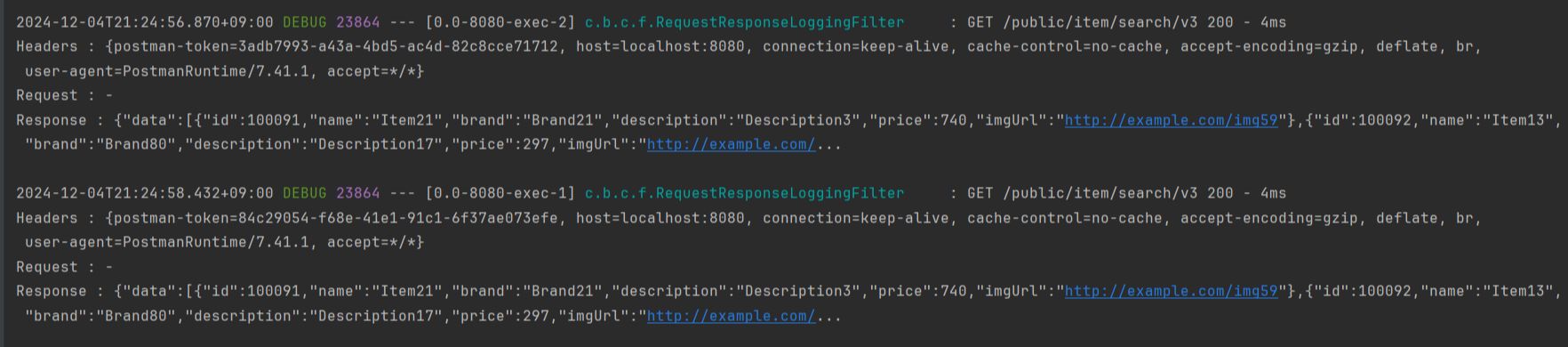
최초의 API 요청 이후, 이후의 요청들은 select 쿼리가 나가지 않고 캐시된 데이터를 반환하는 것으로 확인되었다.
불필요한 DB 접근을 줄였고 이 개선 사항으로 성능이 얼마나 향상될지
Ngrinder 테스트 툴을 사용해서 정확하게 측정해보겠다.
1. Cache 적용 전 Ngrinder 부하테스트 결과
1-1. Ngrinder Script
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.assertThat
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import java.util.Random
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
private static final Random random = new Random()
private static final String sortOption = "추천"
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(30000)
test = new GTest(1, "http://ec2-54-180-248-72.ap-northeast-2.compute.amazonaws.com")
request = new HTTPRequest()
grinder.logger.info("Before process setup.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("Before thread setup.")
}
@Before
public void before() {
grinder.logger.info("Initializing test.")
}
@Test
public void test() {
// parameters
String sort = URLEncoder.encode(sortOption, "UTF-8") // 인코딩 꼭 해줘야 한다
int page = random.nextInt(10) + 1 // 1 ~ 10 페이지 중 랜덤
int size = 10
String url = String.format("http://ec2-54-180-248-72.ap-northeast-2.compute.amazonaws.com:8080/public/item/search?sort=%s&page=%d&size=%d", sort, page, size)
grinder.logger.info("Request URL: {}", url)
HTTPResponse response = request.GET(url)
assertThat(response.statusCode, is(200))
grinder.logger.info("Response received with status: {}", response.statusCode)
}
}
홈 화면에 로드되는 sort 옵션은 "추천" 이기 때문에 해당 parameter 로 script 작성해줬다.
< Ngrinder performance test 설정 항목값 >
처음에 Vuser per agent 2500 으로 세팅해줬더니
부하가 너무 심하고 테스트 시간 3분도 채가지 못해서 2000 으로 낮추어서 다시 테스트 세팅해주었다.
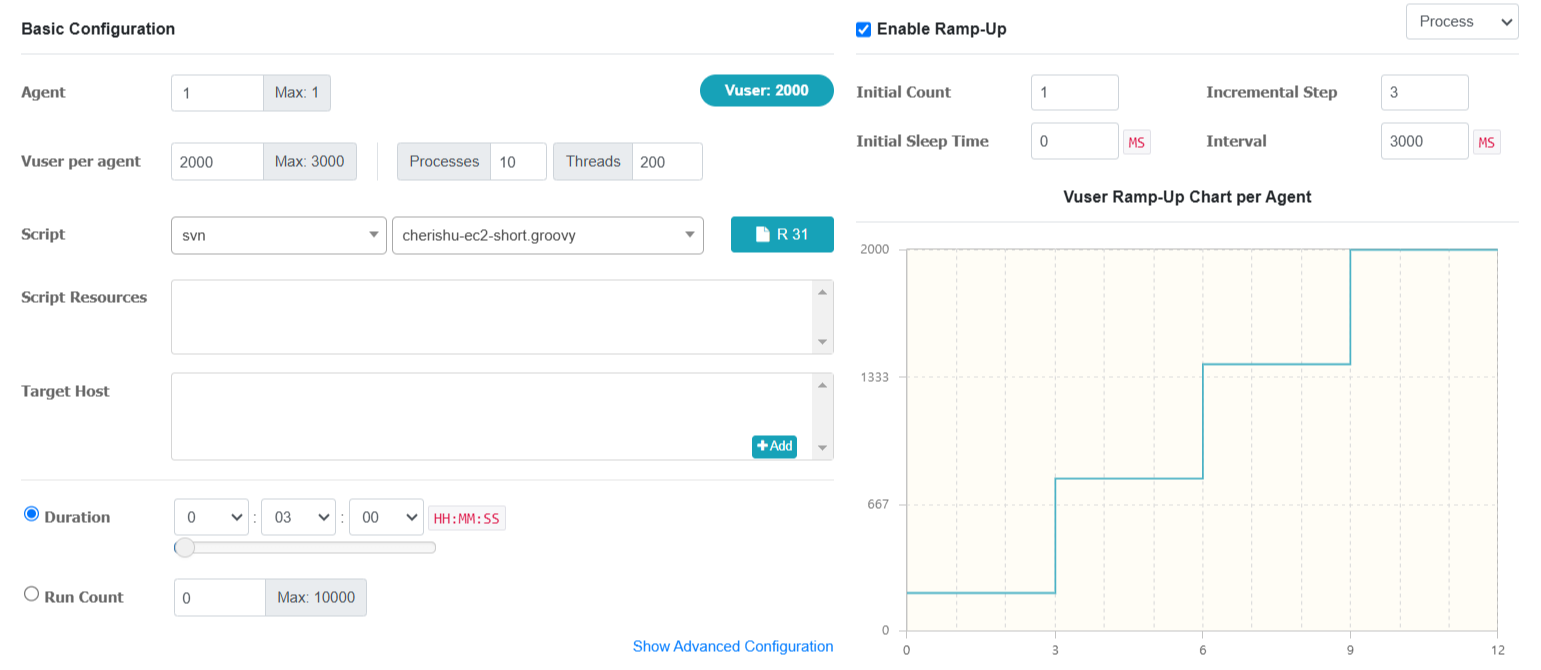
최종 test 세팅값입니다.
Enable Ramp- Up
+ Initial Count (초기 카운트) - 1
+ Incremental Step (증가 단계) - 3
+ Interval (간격) - 3000ms
부하를 주기 위한 Enable Ramp-Up 조건을 enable 해주었고
2000 명에서 3초 간격으로 3명씩 추가되며, 1, 4, 7, 10, 13, 16 ... 이런 식으로 3명씩 증가하게 된다.
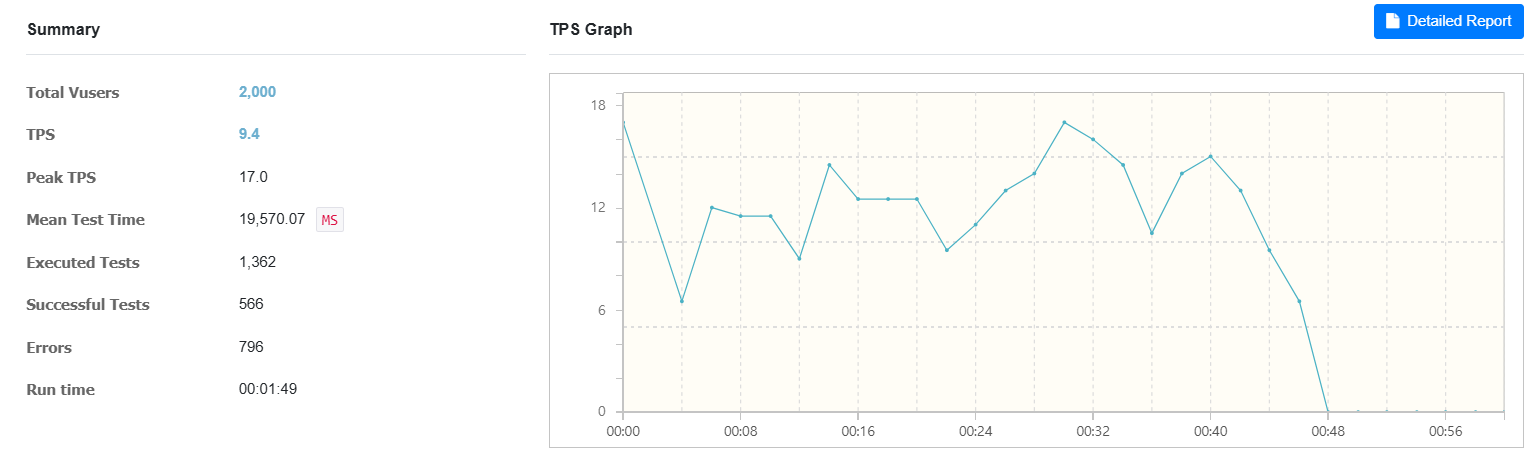
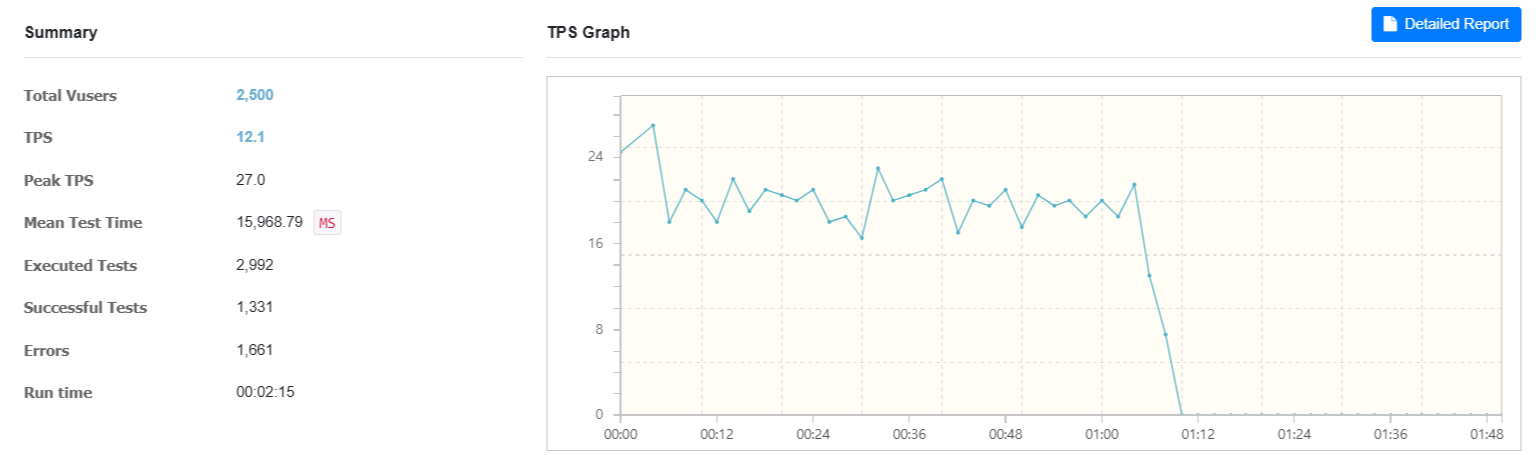
그래프를 보면 TPS(Transactions per Second)가 급격히 떨어지면서 Errors 수치가 급증하고
테스트가 더 이상 진행되지 않되고 있음을 볼 수 있다.
처음에 높은 부하를 받아서 처리하다가 이후 요청이 쌓이고 더이상 처리할 수 없어서 0으로 급락해버렸다.
2.Cache 적용 후 Ngrinder 부하테스트 결과
2-1. Ngrinder Script
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.assertThat
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import java.util.Random
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
private static final Random random = new Random()
private static final String sortOption = "추천"
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(30000)
test = new GTest(1, "http://ec2-54-180-248-72.ap-northeast-2.compute.amazonaws.com")
request = new HTTPRequest()
grinder.logger.info("Before process setup.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("Before thread setup.")
}
@Before
public void before() {
grinder.logger.info("Initializing test.")
}
@Test
public void test() {
// parameters
String sort = URLEncoder.encode(sortOption, "UTF-8") // 인코딩 꼭 해줘야 한다
int page = random.nextInt(10) + 1 // 1 ~ 10 페이지 중 랜덤
int size = 10
String url = String.format("http://ec2-54-180-248-72.ap-northeast-2.compute.amazonaws.com:8080/public/item/search/v2?sort=%s&page=%d&size=%d", sort, page, size)
grinder.logger.info("Request URL: {}", url)
HTTPResponse response = request.GET(url)
assertThat(response.statusCode, is(200))
grinder.logger.info("Response received with status: {}", response.statusCode)
}
}
1-1 script 와 바뀐건 캐시를 적용해준 v2 요청 API 부분이다.
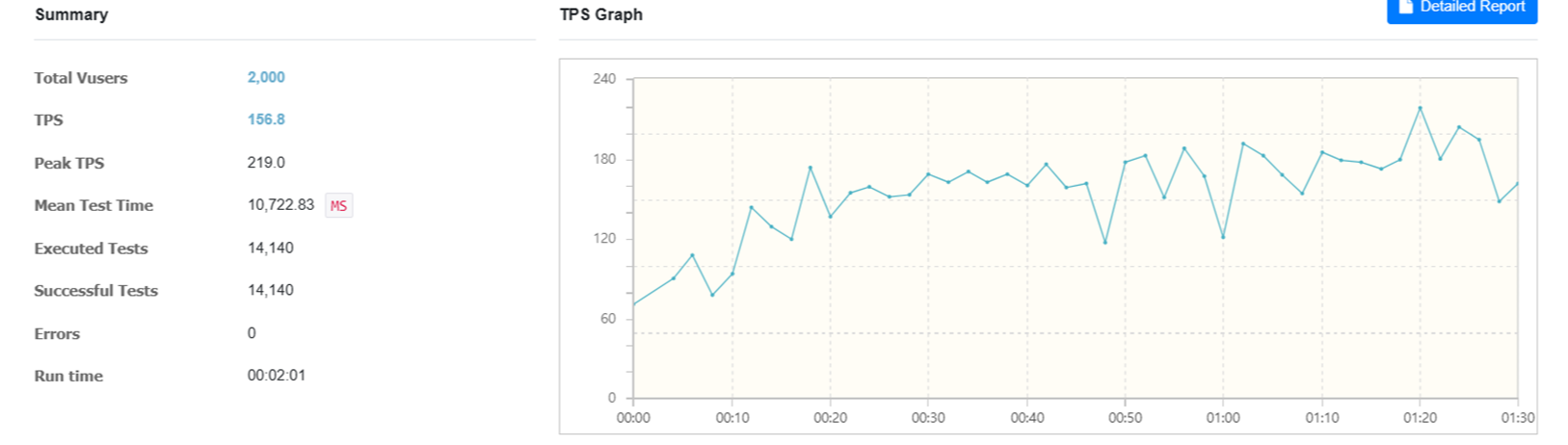
그래프를 보면
캐싱을 적용한 후 TPS의 변동성이 줄어듦과 동시에 156.8으로 처리량도 월등히 높아졌으며,
Ramp up 으로 점진적 부하 를 계속 주고 있음에도 테스트 중후반에도 전체적으로 훨씬 안정적인 상태를 보인다.
Peak TPS도 이전보다 높으며, 지속적으로 높은 수준을 유지하고 있다.
3.캐싱 적용 전 vs 후 분석 (Vusers: 2000)
- TPS (Transactions Per Second):
- 적용 전: 9.4
- 적용 후: 156.8 (약 16.7배 증가)
- 성공 테스트 수 (Successful Tests):
- 적용 전: 566
- 적용 후: 14140 (약 25배 증가)
- 오류 수 (Errors):
- 적용 전: 796
- 적용 후: 0
TPS 처리량이 약 1567% 향상 되고 오류 수는 0 건으로 100% 감소시키는데 성공하였다.


그리고 ngrinder agent CPU와 Memory 사용량도 보면
✔ 캐시 적용 전 CPU 사용량은 6.3%에서 99%까지 스파이크가 튀며 안정적이지 않은 상태를 지속적으로 보여줬지만
✔ 캐시 적용 후 CPU와 Memory 사용량은 최대 70%에서 50%대를 안정적으로 유지하고 있었다.
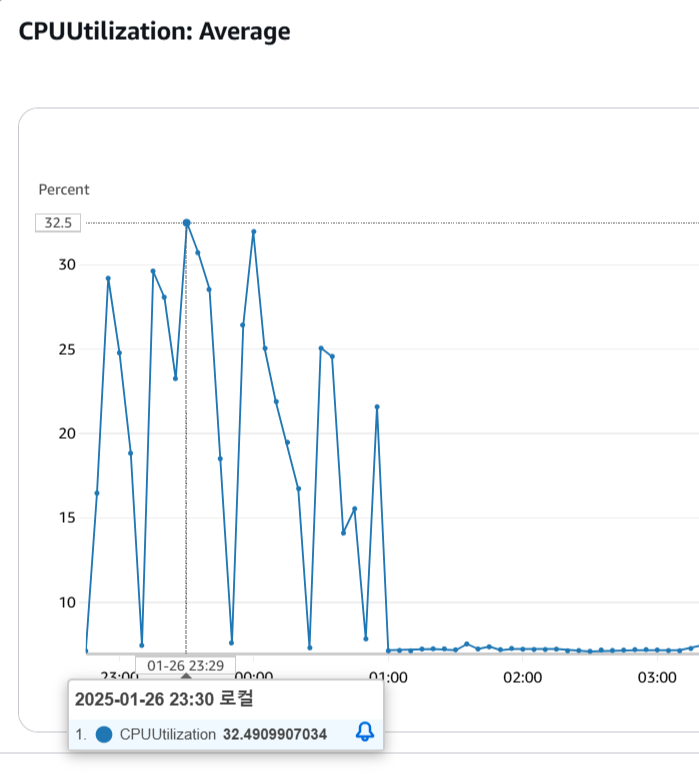
부하테스트를 진행한 ec2 CPU 사용량도 살펴보았다.
총 7번의 부하테스트를 진행해봤는데 최대 32.5%로 60%를 목표로 진행했던 부하테스트보다 훨씬 무리가 덜 갔다.
캐시 적용 초기에는 CPU 부하가 높았으나,
반복 요청을 처리하면서 캐시 적중률이 상승해 CPU 사용량이 안정적으로 낮아지는 모습도 확인할 수 있었다.
4. 느낀점
부하 테스트 이후, 다른 프로젝트에도 Caffeine 캐시를 적용해보니 이번에는 성능 개선도가 크지 않았다.!

그 이유는 해당 query가 크게 복잡하지 않았고
해당 테이블에 이미 적절한 Index 를 생성해두어 Index Only Scan으로 query 실행 시간이 짧았기 때문으로 보인다.
따라서 부하 테스트 결과 TPS 성능에서 큰 차이가 없었다면,
데이터의 변동성, Index 생성에 따른 Memory 사용량, Cache 생성 비용 등을 종합적으로 고려해서
최적의 방법을 선택하는 것이 중요하다는 걸 느꼈다.
새로운 기술 적용은 언제나 그렇듯 항상 캐시를 적용하는 것도 최적의 해결책이 될 수는 없으며
query 최적화나 DB 실행 계획 분석 후 구조 개선 후 Cache 적용을 해보면 좋을 것 같다는 생각이 들었다.